



The voice agent I run in production has no two identical calls. The speech model phrases things differently every time, the transcription layer mishears words at its own whim, and callers — real or simulated — never say anything the same way twice. Classic testing assumes you can pin inputs and assert outputs. Here, the inputs won’t hold still and the outputs are paraphrased.
This post is the testing playbook that emerged from shipping anyway: a layered pyramid that ends in LLM-as-a-judge evaluation over live model-to-model phone calls, the statistical discipline that keeps non-determinism from gaslighting you, and the two failure modes of judge-based testing that cost me the most time — a judge that scores the wrong transcript, and a judge that enforces the wrong rules.
Why conventional tests stop working
A voice agent has three stacked sources of non-determinism: the realtime speech model (different wording, different tool-call timing every run), the speech-to-text layer (mishearings, cumulative-transcript artifacts, words merged across sentence boundaries), and the conversation partner. Assert an exact utterance and the test fails on a synonym. Assert nothing and the test passes while the agent talks over the caller. The escape is to stop asserting strings and start asserting properties — and to accept that some layers of the test suite are probabilistic, then engineer around that honestly instead of pretending otherwise.
The pyramid


Layer 1: pure policy unit tests. Everything that can be deterministic, must be. Gating rules (“may the call end?”), state machines, field-validation logic, persistence filters — extracted into small dependency-injected modules with no I/O and no timers, tested in milliseconds. The architectural pressure is the point: code you can’t unit test this way is code with too many owners. When a live failure is root-caused, the fix lands here first as a deterministic regression test.
Layer 2: mocked-LLM integration tests. The system makes dozens of internal LLM classifier calls (is this a goodbye? does this look like a person’s name?). In this layer the LLM client is mocked with verdicts pinned per payload — “for this exact text, the classifier answers true” — so the orchestration around the classifiers is tested deterministically: caching, retries, fallbacks, what happens when a verdict arrives late or not at all. The mock answers by matching on payload content, not call order; order-based mocks rot instantly in concurrent code.
Layer 3: live model-to-model calls. The real agent — production code, production prompts, real speech models — gets called by a simulated caller: another LLM given a persona and a goal (“you want an appointment; you don’t know which provider; you offer your number when asked”) speaking over an actual audio bridge, with deliberate perturbation injected so transcripts are imperfect in the way real telephony is imperfect. These tests take a minute or two each and no two runs are alike. That’s not a flaw; the variance is the coverage.
Layer 4: judgment and replay. Each live call’s transcript, tool calls, and captured data go to an LLM judge for a structured verdict — and every interesting production failure gets distilled into a replay scenario at this layer, so the exact perturbed phrasing that broke a real call becomes a permanent test case.
Designing the judge
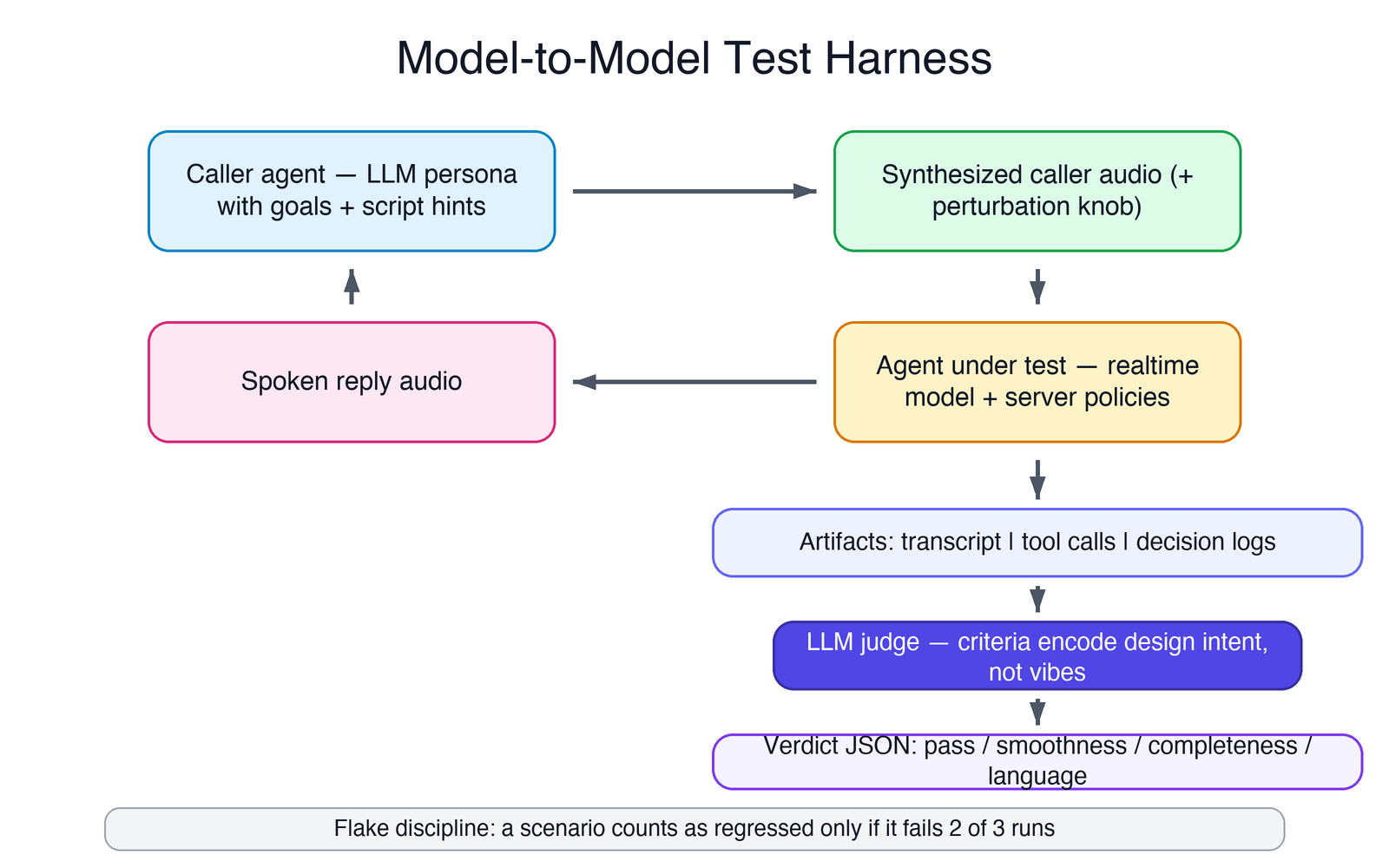
The judge is an LLM given the conversation transcript, the tool-call log, the captured fields, and a rubric. It returns structured JSON — pass/fail, a one-sentence reason, and sub-verdicts for conversation smoothness, data completeness, and language correctness — plus scenario-specific hard rules (“the first ask for a provider must be open-ended; names may be listed only after the caller declines”).
Three design rules carried all the weight:
- Criteria encode design intent, not vibes. A generic “was this a good call?” judge is useless and capricious. Every criterion should trace to a product decision. And when the judge fails something the system intended — mine once failed calls where an unknown provider name was correctly recorded by name rather than matched to a roster, which was exactly the designed behavior — you fix the rubric, not the code. Judge calibration is part of the engineering, with its own review.
- The judge can only punish what the agent could control. A required field the caller explicitly refused to give is not a completeness failure; an answer the caller never provided cannot be extracted. Without these carve-outs, the judge trains you to “fix” correct behavior.
- Dump the judged transcript on every failure. The single highest-leverage line of test infrastructure I wrote. Which leads to…
The transcript integrity trap
The nastiest class of false verdicts wasn’t the judge’s fault: the transcript it scored didn’t match the audio the caller heard. Server-side bookkeeping was silently dropping some audible turns from the stored transcript and flagging others as cancelled when they had actually played. The judge scored dead air where the caller had heard a complete, correct answer — and engineers (me) chased phantom bugs in the dialog logic for days.
The invariant that ended it: a turn the caller audibly heard must appear in the judged transcript, and a turn that never played must not. Enforce it in the runtime, and print the judge’s exact filtered view on every failure so a mismatch is visible in seconds instead of days. If you adopt one thing from this post, adopt this — judge-based testing is only as honest as the artifact being judged.
Flake discipline: the 2-of-3 rule
With three stacked sources of randomness, single runs lie. The same build produced a 4-of-6 failure batch and a 6-of-6 pass within the hour. The discipline that kept me sane:
- A scenario only changes state — regressed or fixed — when it shows the new result in two of three runs. One run is an anecdote.
- Never optimize against a single full-suite run. Re-verify candidate regressions individually before touching code; in my last full sweep, three of five “new failures” vanished on a second run while two were real bugs.
- Budget for the tail. Some scenarios are adversarial by construction (a caller who names an unknown provider, ignores a question, and hangs up in one breath). They earn a known-flaky designation with documented mechanisms, not endless re-runs — and their persistent failure modes feed the next structural fix rather than another patch.
Replay-driven testing
The best test scenarios aren’t invented; they’re transcribed. When a production call goes wrong, the caller’s actual (mis-transcribed, run-on, mid-sentence-corrected) utterances become the simulated caller’s script — preserving the exact ASR weirdness that triggered the bug, because the merged sentence boundary or cumulative-transcript replay usually was the bug’s trigger. A library of these replays is worth more than a hundred synthetic happy paths: it encodes how your callers actually talk.
What this buys you
The pyramid’s deterministic layers run on every change in seconds and catch logic regressions before any audio plays. The live layer plus judge catches what no mock can: prompt regressions, model-behavior drift, races between server interventions and live speech, latency cliffs. And because every live-layer failure is reconstructed from decision-level logs rather than re-run and prayed over, each one terminates in either a code fix with a deterministic test, a rubric fix, or a documented flake — never in a shrug.
This is the second post in a series on production voice agents. The first covered the architecture — who owns the next turn; the next covers observability: writing voice-agent code that an AI can debug from logs alone.