I built the same production voice agent three times. Same requirements, same telephony stack, same speech models available — three fundamentally different architectures. The first one collapsed under its own coupling: every bug fix broke something else. The second one was controllable and correct, and it destroyed the one thing a voice agent exists for: responding like a human, immediately. The third one is the only one that survived contact with real callers.
This post is the architecture write-up I wish I’d read before spending months and real money finding out the hard way. It’s about one question that turns out to decide everything: who owns the next turn?
The problem shape
The agent answers real phone calls. It has to do three things at once, and they pull in different directions:
Hold a natural conversation. Sub-second turn-taking, no dead air, graceful handling of interruptions, callers who ramble, and callers who switch languages mid-sentence.
Capture structured data reliably. A defined set of fields must end up in a database — names spelled right, numbers digit-perfect, nothing invented.
Enforce hard rules. A few behaviors must always happen (reading a phone number back digit by digit) and a few must never happen (hanging up while a required question is unanswered, promising things the business didn’t authorize).
Every architecture below is a different answer to where those three responsibilities live.
Architecture 1: the server-side orchestrator
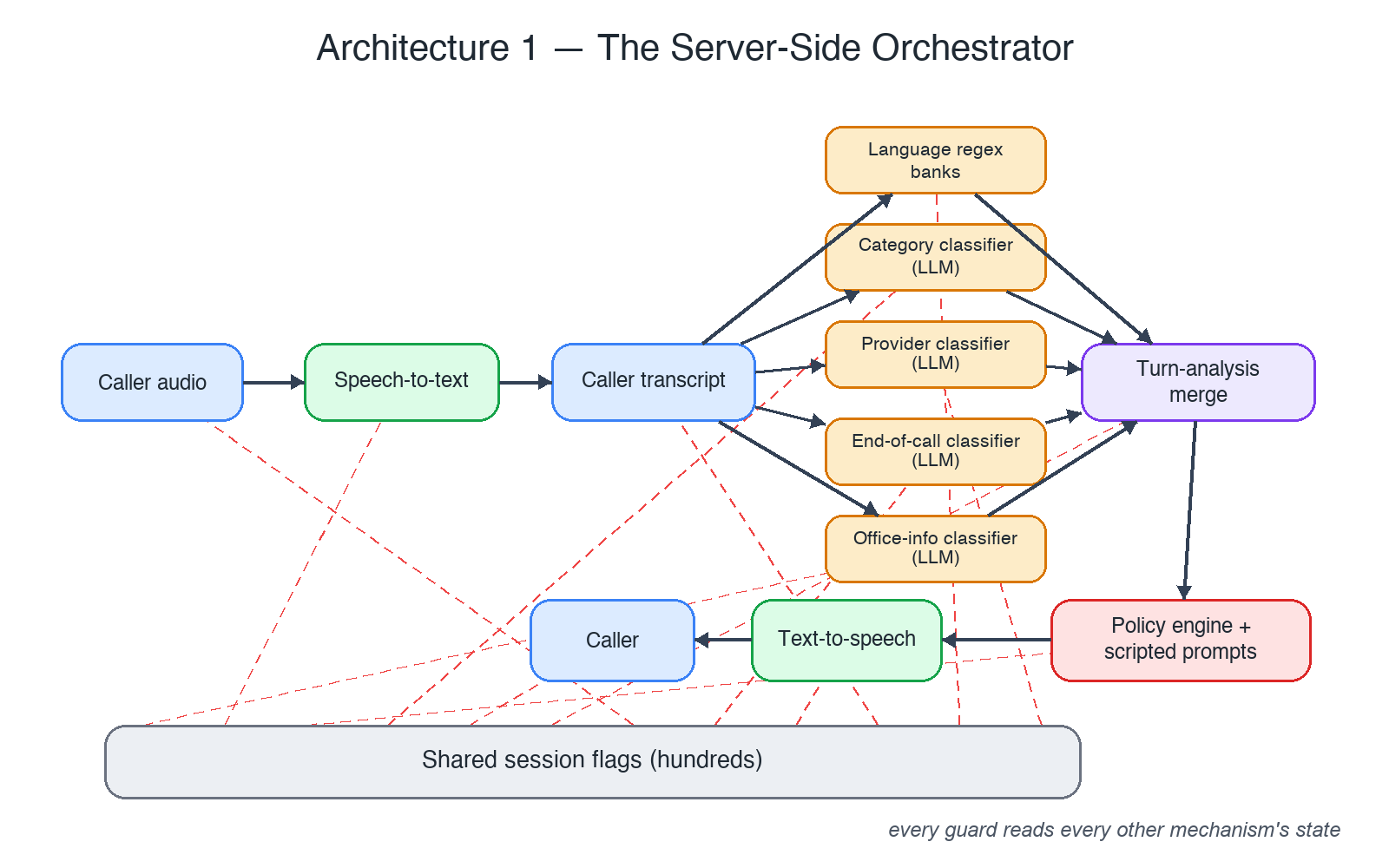
Architecture 1: every caller turn fans out to parallel classifiers; shared flags couple everything to everything.
The first build treated the speech model as a mouthpiece. The server owned everything: each caller utterance was transcribed and fanned out to a battery of parallel classifiers — one deciding the call category, one watching for a provider name, one watching for end-of-call intent, one detecting reference-only questions, plus hand-maintained regex banks for language detection (including phonetic transliterations of “can you speak X to me?” in half a dozen scripts). A merge layer combined their outputs into a “turn analysis,” and a policy engine picked what to say next, often from scripted prompts.
Why it’s tempting
Every decision is inspectable server code. When something goes wrong, there’s a line number.
Each classifier is small, cheap, and unit-testable in isolation.
Adding a rule looks easy: write another classifier, wire it into the merge.
Scripted prompts give you word-level control over what the agent says.
Why it collapsed
The classifiers were never actually independent. The merge layer and a growing web of shared session flags meant every concern’s guard read every other concern’s state. The provider gate needed to know about the end-of-call state; the end-of-call logic needed to know whether a language switch was pending; the language logic needed to know whether a scripted prompt was mid-playback. Fixing a bug in one guard reliably broke an invariant another guard depended on. This is the “too intertangled” failure: the system had no single owner for any decision, so every decision was made N times by N pieces of code that disagreed at the margins.
Regex banks don’t survive multilingual reality. The language-detection patterns grew into a museum of transliterations and edge cases — unfalsifiable, unreviewable, and wrong in ways you only discover on a live call. Every new language meant re-deriving every pattern. The model I was routing around already understood all of these languages natively.
Latency stacked. Multiple classifier round-trips per turn, then a policy decision, then speech synthesis. Each piece was fast; the pipeline wasn’t.
Mid-turn disagreement. When two classifiers fired at once — caller names a provider and says goodbye in the same breath — two subsystems both believed they owned the next turn. Most of the audible bugs (double prompts, talking over the caller, contradictory follow-ups) were exactly this.
The deep lesson from architecture 1: distributed decision-making without a single owner is the bug. It doesn’t matter how clean each component is; if N components can each initiate speech, you ship race conditions to people’s ears.
Architecture 2: server-gated turn-taking
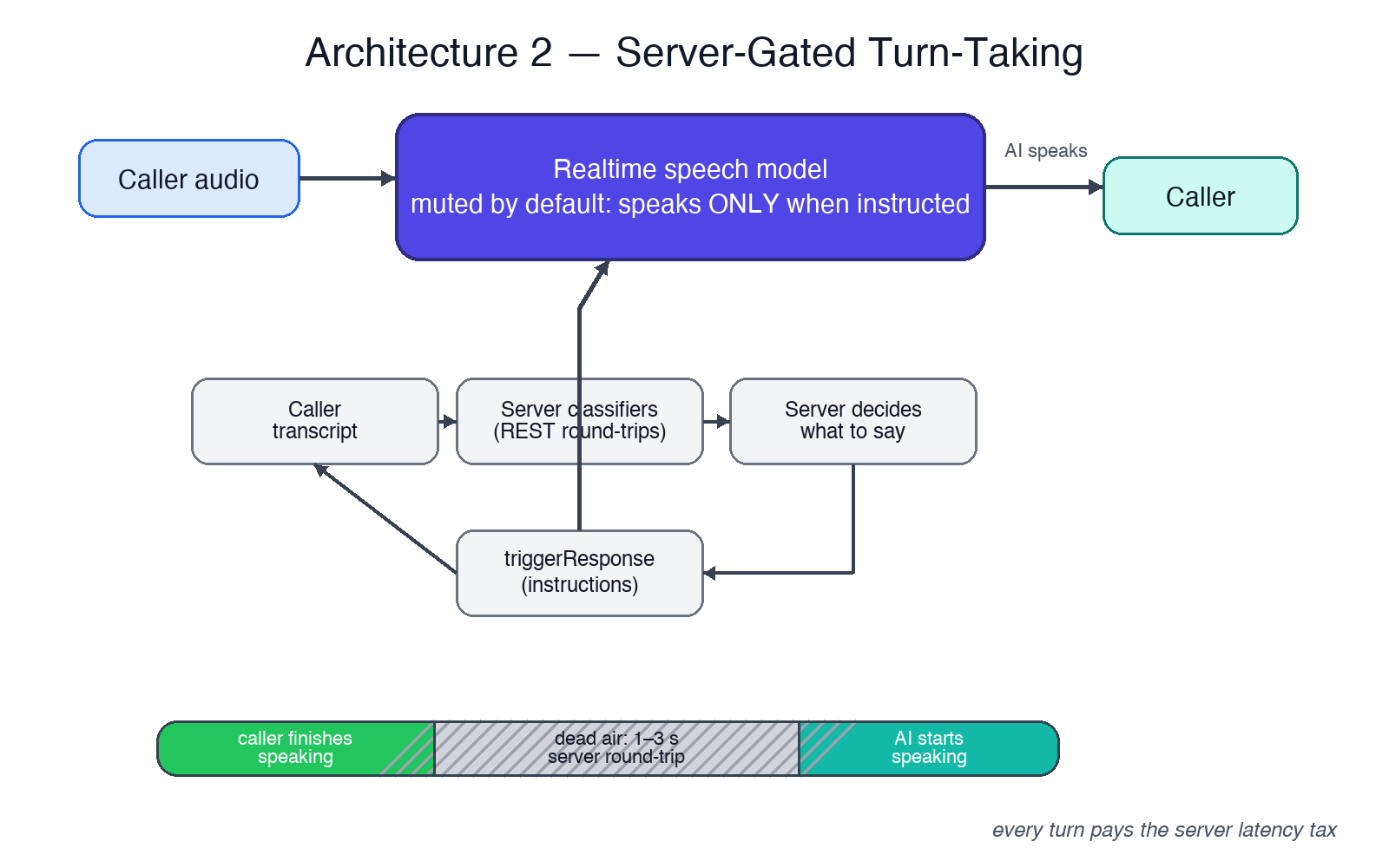
Architecture 2: one decider, full control — and a server round-trip of dead air on every single turn.
The obvious fix for “too many deciders” is one decider. The second build made the server the single owner of every turn: the realtime speech model was muted by default and spoke only when the server explicitly triggered a response with instructions. Caller speaks → transcript → server classifies → server decides what should be said → server instructs the model to say it.
What it bought
Maximal control. The agent literally could not speak unscripted. “Never say X” became enforceable; compliance reviews got easy.
A familiar mental model. Request in, decision, response out — it’s a web app with audio attached. Easy to reason about, easy to log, easy to test piece by piece.
One owner per turn. The race conditions from architecture 1 mostly disappeared.
What it cost
Dead air, every single turn. The caller stops speaking; the server spends one to three seconds classifying and deciding; only then does audio start. Humans interpret that silence as a broken line. They say “hello?”, repeat themselves, talk over the agent’s late reply — and now the turn-taking is corrupted on top of being slow.
It threw away the realtime model’s superpower. Modern speech-to-speech models do sub-second turn-taking with native prosody and instant barge-in handling. Gating them behind a server loop converts an interactive medium back into an IVR. Callers behave accordingly.
The classifiers didn’t go away. The server still had to understand every utterance to decide the next move — so all the classification machinery (and most of its coupling) survived, now sitting directly on the latency-critical path.
The deep lesson from architecture 2: in voice, latency is not a performance metric — it’s the product. An architecture that adds a server round-trip to every turn has already failed, no matter how correct it is. The latency budget for feeling human is roughly half a second; classification pipelines don’t fit in it.
Architecture 3: the model owns the conversation
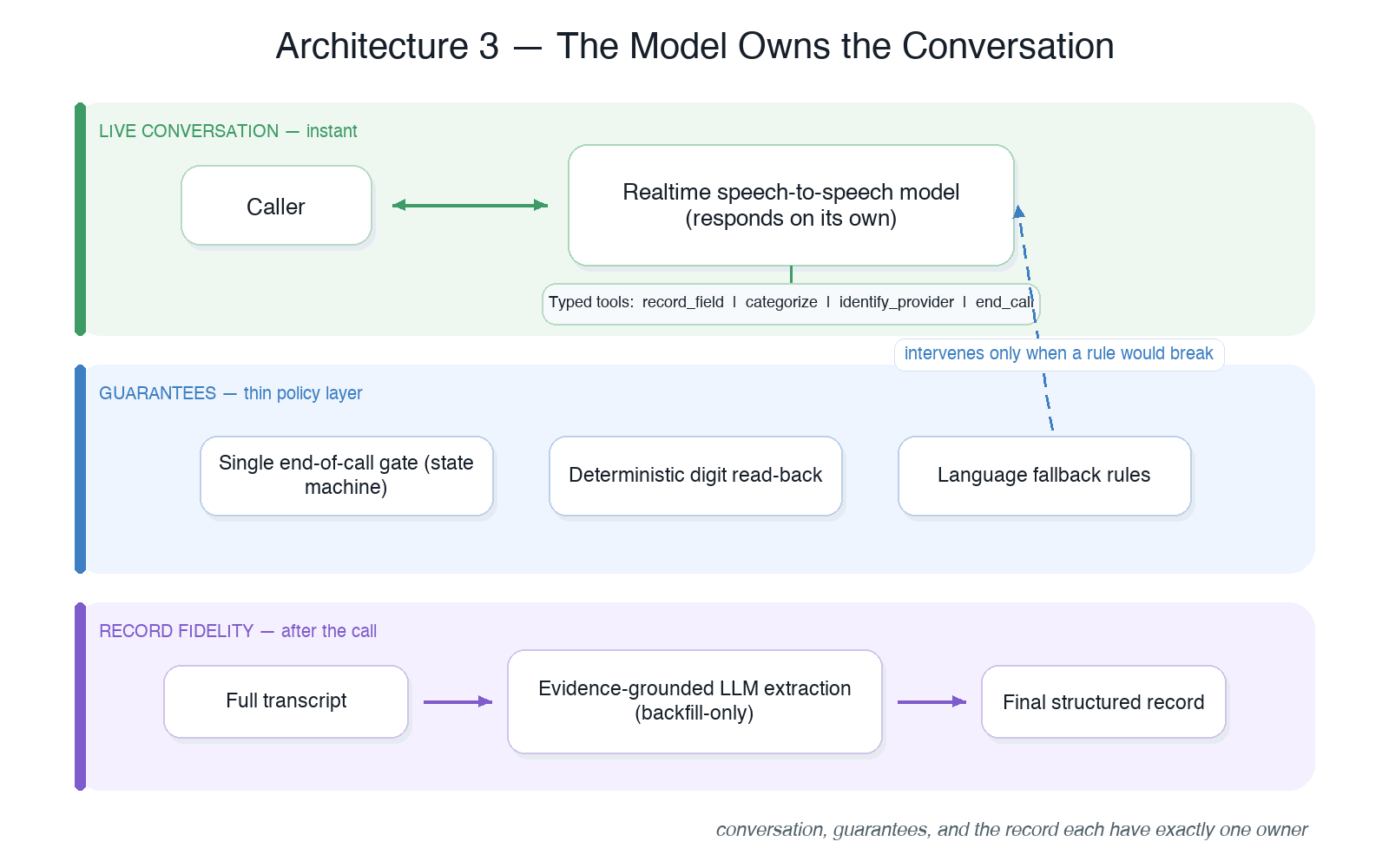
Architecture 3: conversation, guarantees, and the record each have exactly one owner.
The third build inverts the relationship, and it’s the one that works. The realtime speech-to-speech model owns the conversation outright: it hears the caller, decides what to say, and says it — immediately, with no server gate. Everything the server cares about is expressed through three separate channels, each with exactly one owner:
Live conversation → the model. The model auto-responds. State capture happens through typed tools — one small, well-described tool per field it must record, plus tools for categorizing the call, resolving a provider, and ending the call. Tool results carry steering (“recorded; ask for the next missing field: X”) so the model always knows the next move without the server composing its sentences. Language handling comes free: the model natively follows the caller across languages, and the regex museum from architecture 1 got deleted.
Hard guarantees → a thin policy layer. The server enforces only what the model cannot guarantee: a single end-of-call gate (a small state machine — one canEndCall(), one closing, one teardown timer) that makes it structurally impossible to hang up with required questions unanswered or to play two goodbyes; deterministic digit-by-digit read-back for phone numbers; language fallback rules for unsupported locales. Crucially, the policy layer intervenes; it doesn’t drive. It acts only when a rule would otherwise break.
Record fidelity → a post-call pass. Here’s the trick that removed the most code: stop trying to win the live race for data quality. After the call ends, a worker runs one LLM extraction over the full transcript for any required field the live call missed — backfill-only (it never overwrites what the live call captured) and evidence-grounded (every recovered value must quote a verbatim caller utterance; no quote, no write). The live system only needs capture good enough for steering; the office-facing record is reconciled afterward, with the complete conversation in hand and zero latency pressure.
What it costs (honestly)
Non-determinism is real. The model will occasionally acknowledge an answer — “Got it” — without calling the record tool. That’s precisely why the post-call pass exists, and why every server guard verifies model claims instead of trusting them. The single most instructive bug I shipped: a code path that ended calls because an upstream component claimed “all required fields collected” in a reason string. Verify; never trust.
Your prompt and tool schemas become an API surface. Tool descriptions, steering strings, and instruction text need the same review discipline as code, because they are code.
Testing gets harder. You can’t assert exact utterances anymore. You need simulated callers, an LLM judge scoring transcripts against design intent, and statistical discipline about flakes. (That’s the next post.)
You give up word-perfect scripting — except where it matters, where the policy layer injects the handful of deterministic prompts that must be exact.
The principle underneath
Looking back across all three builds, nearly every user-audible failure had the same root: two subsystems both believed they owned the next turn. Two goodbyes played back to back. A scripted prompt talking over a live answer. A re-asked question the caller had already answered. Different symptoms, one disease.
So the architecture question for voice agents isn’t “how do I control the model?” It’s an ownership ledger:
The conversation has one owner: the realtime model.
Each hard guarantee has one owner: a small, boring, unit-testable policy module — and cross-cutting state like end-of-call gets a real state machine, not a pile of cooperating flags.
The record has one owner: a post-call reconciliation pass that doesn’t race anyone.
Rules I now hold as defaults for any voice agent:
Never put a server round-trip between the caller and the agent’s voice. If a check can’t run async or after the call, it doesn’t belong in the turn loop.
One owner per decision. If two code paths can both initiate speech or both end the call, you’ve already shipped the bug.
Verify, never trust. Model (and policy) claims about state are hypotheses until checked against the actual data at a single shared gate.
Backfill-only, evidence-grounded recovery. Let the transcript be the source of truth for the record — after the call, with a quote required for every extracted value.
No language-specific code. If you’re writing a regex for how people say something, you’re re-implementing the model, badly, one language at a time.
Log decisions, not just events. Every gate verdict, every recovered field, every intervention — one greppable line each. Voice bugs are reconstructed, not reproduced.
The third architecture isn’t cleverer than the first two — it’s humbler. It stops fighting the realtime model for the steering wheel, narrows the server to the few promises only a server can keep, and moves correctness to the one place that has the whole conversation and no clock: after the call.
Next in this series: how we test this thing — simulated callers, LLM-as-a-judge scoring, and the statistical discipline you need when your test subject is non-deterministic.
Farid Fadaie is the cofounder and CEO of Viva AI, and a San Francisco-based product leader and engineer working at the intersection of AI, healthcare operations, and dental technology. He has built products across privacy, peer-to-peer systems, dental software, and real-world practice operations.